Introduction
In the modern banking industry, maintaining a single, trusted view of customer data is critical for regulatory compliance, risk management, and personalized customer experiences. This case study outlines the implementation of an Informatica Master Data Management (MDM) on-premises solution for a large banking institution with multiple legacy systems.Problem Statement
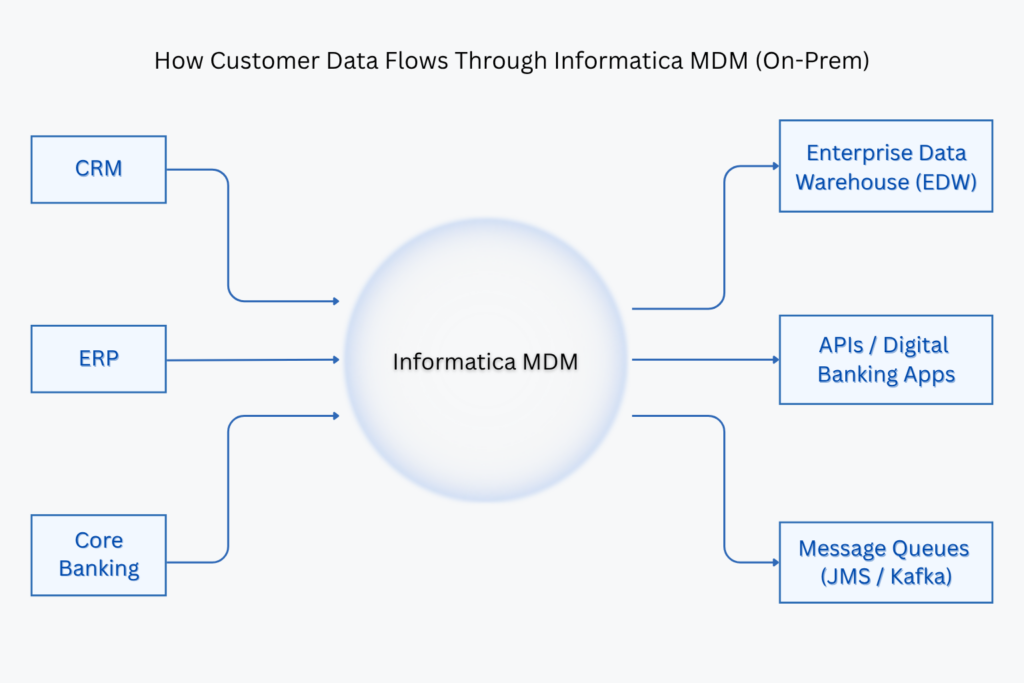
The problem statement highlights the challenges faced by the banking institution due to fragmented customer data across multiple systems, including ERP, CRM, and Core Banking Systems. This led to data redundancy, with multiple records for the same customer, and inconsistent customer data due to different formats and outdated records. The bank also struggled with regulatory compliance, making it difficult to track and audit customer transactions. Integration challenges arose due to the absence of a centralized customer repository, impacting API-driven digital banking initiatives. Lastly, the bank needed a solution capable of handling large-scale data processing, managing 100 million records with a daily ingestion rate of 5 million records.Solution Overview
To address these challenges, the bank partnered with Agenthum solutions, a leader in data management solutions, to implement an on-premises Informatica MDM solution. Agenthum Solutions provided expertise in Data Analysis, Data Ingestion, Matching and Merging, User Interface Configuration,Publishing and Real-time Services. Agenthum Solutions implemented Informatica MDM HUB as a centralized Customer Data Platform (CDP) using the following architecture components: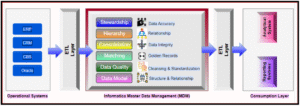
High level Architecture Diagram: Informatica MDM
 Image: Informatica MDM Architecture Diagram
Image: Informatica MDM Architecture Diagram
Source Systems & Data Extraction
- Data is extracted from ERP, CRM, and Core Banking Systems using ETL pipelines.
- Oracle Database acts as the staging area for extracted customer data.
- Tokenization is applied to protect Personally Identifiable Information (PII).

Informatica MDM Processing
The Informatica MDM processing workflow involves multiple stages to ensure data accuracy and consistency. Data from various source systems is first stored in the Landing Table (L_CUST) before moving to the Staging Table (C_L_CUST) for transformation. Change Data Capture (CDC) identifies modified records, ensuring efficient updates. Data deduplication is performed using phonetic, fuzzy, and exact matching algorithms, while trust and validation rules help create a “golden record” stored in the Master Table (B_CUST). Lookup tables store reference data for seamless integration.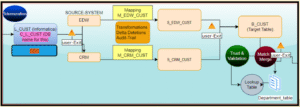
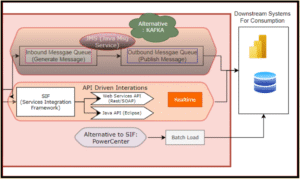
Data Publishing & Downstream Consumption
For data publishing and downstream consumption, the mastered data is distributed to multiple systems. It is loaded into the Enterprise Data Warehouse (EDW) for analytical insights, exposed via API services for digital banking applications, and transmitted through message queues (JMS/Kafka) for real-time updates. Additionally, batch load processes synchronize bulk data with external applications.