Background
A leading provider of advanced data solutions, was experiencing significant performance bottlenecks in its data processing pipelines. The company relied on legacy systems that could not keep pace with rapidly growing data volumes, leading to delays in analytics and reporting. These issues not only hampered operational efficiency but also increased operational costs and customer dissatisfaction.
Challenges
- Performance Bottlenecks:
Existing data pipelines suffered from latency and inefficiencies, leading to delayed reporting. - Scalability Issues:
As data volume grew, the system struggled to process data within the required SLAs. - Manual Processes:
Several operational tasks required frequent manual intervention, increasing the risk of errors. - Lack of Documentation:
Limited documentation made onboarding and troubleshooting difficult.
Solutions & Implementation
1. Enhancing Data Processing Pipelines
Challenges in Existing Pipelines
The organization’s data processing pipelines faced several issues:
- Slow Data Processing:
Large volumes of data were being processed inefficiently, leading to delays in analytics and reporting. - Unoptimized Queries:
Poorly structured SQL queries and transformations in BigQuery resulted in high compute costs and slow execution. - Scalability Issues:
The pipelines were not designed to handle increasing data volumes, leading to performance degradation. - Data Quality & Reliability Problems:
Frequent failures and missing data in downstream reports were causing business disruptions.
Solutions Implemented
Refactoring Data Pipelines
- Redesigned ETL workflows to optimize data ingestion, transformation, and storage.
- Used Apache Spark & PySpark to efficiently process large datasets in parallel, reducing execution time.
- Migrated legacy batch processing jobs to Cloud Dataflow, allowing real-time streaming capabilities.
Optimizing BigQuery Performance
- Improved SQL query structuring to minimize expensive joins and unnecessary data scans.
- Implemented partitioning and clustering strategies in BigQuery to enhance query performance and reduce costs.
- Used materialized views and incremental processing to avoid full table scans.
Enhancing Data Storage & Retrieval
- Shifted from inefficient row-based storage to optimized columnar storage for faster analytical queries.
- Compressed Cloud Storage data using Parquet format to reduce storage costs and improve read performance.
- Established data lifecycle policies to automatically purge outdated or redundant data.
Error Handling & Resiliency
- Implemented automatic retry mechanisms in pipelines to handle transient failures.
- Added real-time monitoring and logging using Cloud Logging and Stackdriver to detect anomalies early.
- Set up alerting mechanisms via Google Cloud’s monitoring tools for proactive issue resolution.
2. Implementing Scalable Data Solutions
- Migrated and optimized ETL pipelines to leverage BigQuery for faster and more scalable data processing.
- Used Cloud Dataflow for real-time and batch data transformations, reducing overall data processing time.
- Architected CI/CD infrastructure for automated deployment and monitoring of data engineering workflows.
3. Troubleshooting & Root-Cause Analysis
- Conducted in-depth root-cause analysis of complex data issues, improving system reliability.
- Automated logging and monitoring using GCP tools like Cloud Logging and Stackdriver, enabling faster issue resolution.
4. Process Innovation & Automation
- Automated several manual operational tasks to reduce human intervention and enhance efficiency.
- Developed self-healing mechanisms in pipelines to handle failures gracefully and improve reliability.
5. Documentation & Best Practices
- Created runbooks, administration guides, and best practice documents to ensure knowledge retention and ease of troubleshooting.
- Standardized ETL and data pipeline development practices for consistent implementation across projects.
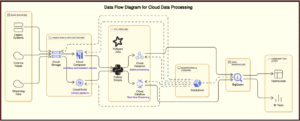
Architecture Diagram
Impact & Results
- 20% reduction in data processing time by optimizing queries and leveraging efficient storage techniques.
- Improved scalability, allowing data pipelines to handle 3x increase in data volume without performance degradation.
- Automated 40% of manual tasks, reducing operational overhead and minimizing errors.
- Mentored and upskilled junior engineers, strengthening the data engineering team’s capabilities.
- Enhanced system reliability, ensuring 99.9% uptime for critical data processes.
Conclusion
By leveraging GCP’s BigQuery, Cloud Storage, and Dataflow, optimizing ETL pipelines with Python and Spark, and implementing robust CI/CD practices, I successfully improved data processing efficiency and system reliability. My leadership in mentoring, documentation, and automation contributed to a more scalable and efficient data engineering ecosystem.